
Tags: Week 1 : Introduction to Machine Learning
What Is Machine Learning?
The field of study that gives computers the ability to learn without being explicitly programmed
- Arthur Samuel(1959)
AI systems need the ability to acquire their own knowledge, by extracting patterns from raw data. This capability is known as machine learning
The representation is the process of transforming data into a format that can be used by a learning algorithm → Representation is to extract patterns from raw data
The performance of machine learning algorithms depends heavily on the representation of the data they are given
the AI system does not examine the patient directly. Instead, the doctor tells the system several pieces of relevant information, such as the presence or absence of a uterine scar
Each piece of information included in the representation of the data is known as a feature. Machine algorithm learns how each of these features of the patient correlates with various outcomes. However, it cannot influence how features are defined in any way
- 출처 : Deep Learning (Adaptive Computation and Machine Learning series)
Types
- Supervised Learning
- Unsupervised Learning
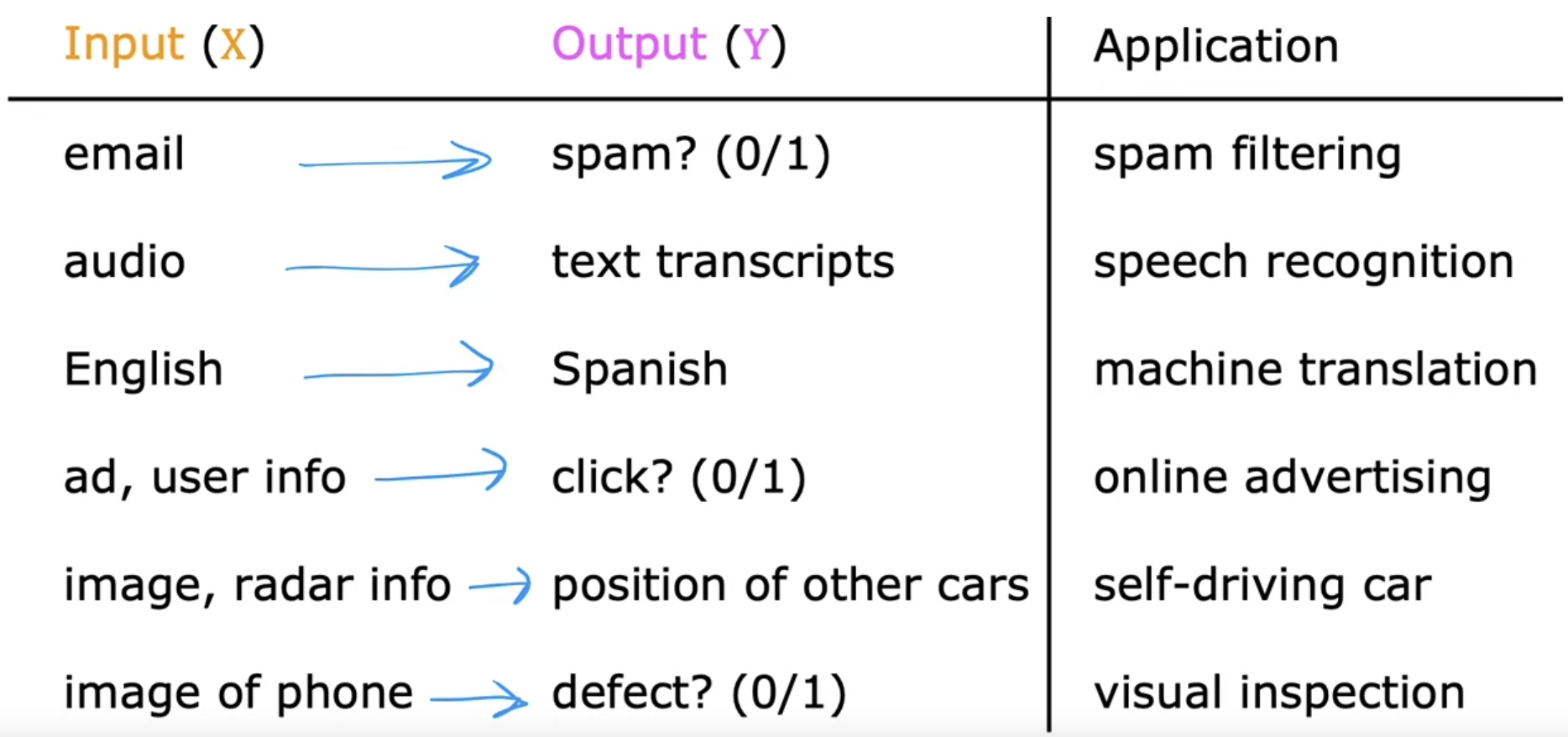
Supervised Learning
Give a learning algorithm examples to learn from being given “Correct Answer”, which is the correct label y for a given input x
Train and Test
- Train your model with examples of inputs x and the right answers, that is the labels y
- After the model has learned from these input(x) and output(y), it can then take a brand new input x that has never seen before, and try to produce the appropriate corresponding output y
Types
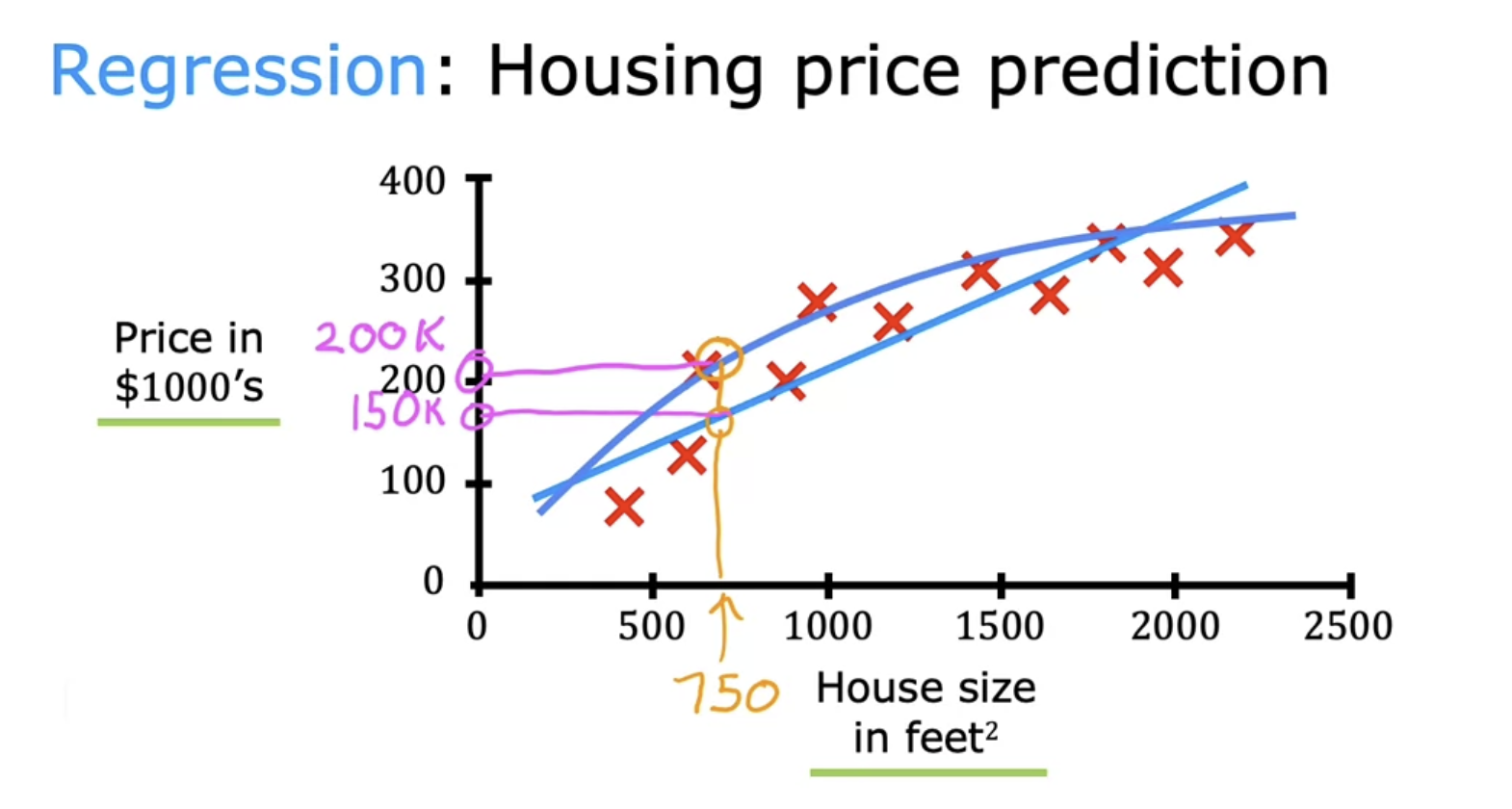
(1) Regression
Predict a number from infinitely many possible numbers such as the house prices in our example, which could be 150,000 or 70,000 or 183,000 or any other number in between
- 출처 : 코세라 강의
Models predict a numerical value given some input. To solve this task, the learning algorithm is asked to output a function $f : R_n→ R$. This type of task is similar to classification, except that the format of output is different. An example of a regression task is the prediction of the expected claim amount that an insured person will make (used to set insurance premiums), or the prediction of future prices of securities. These kinds of predictions are also used for algorithmic trading
- 출처 : Deep Learning (Adaptive Computation and Machine Learning series)
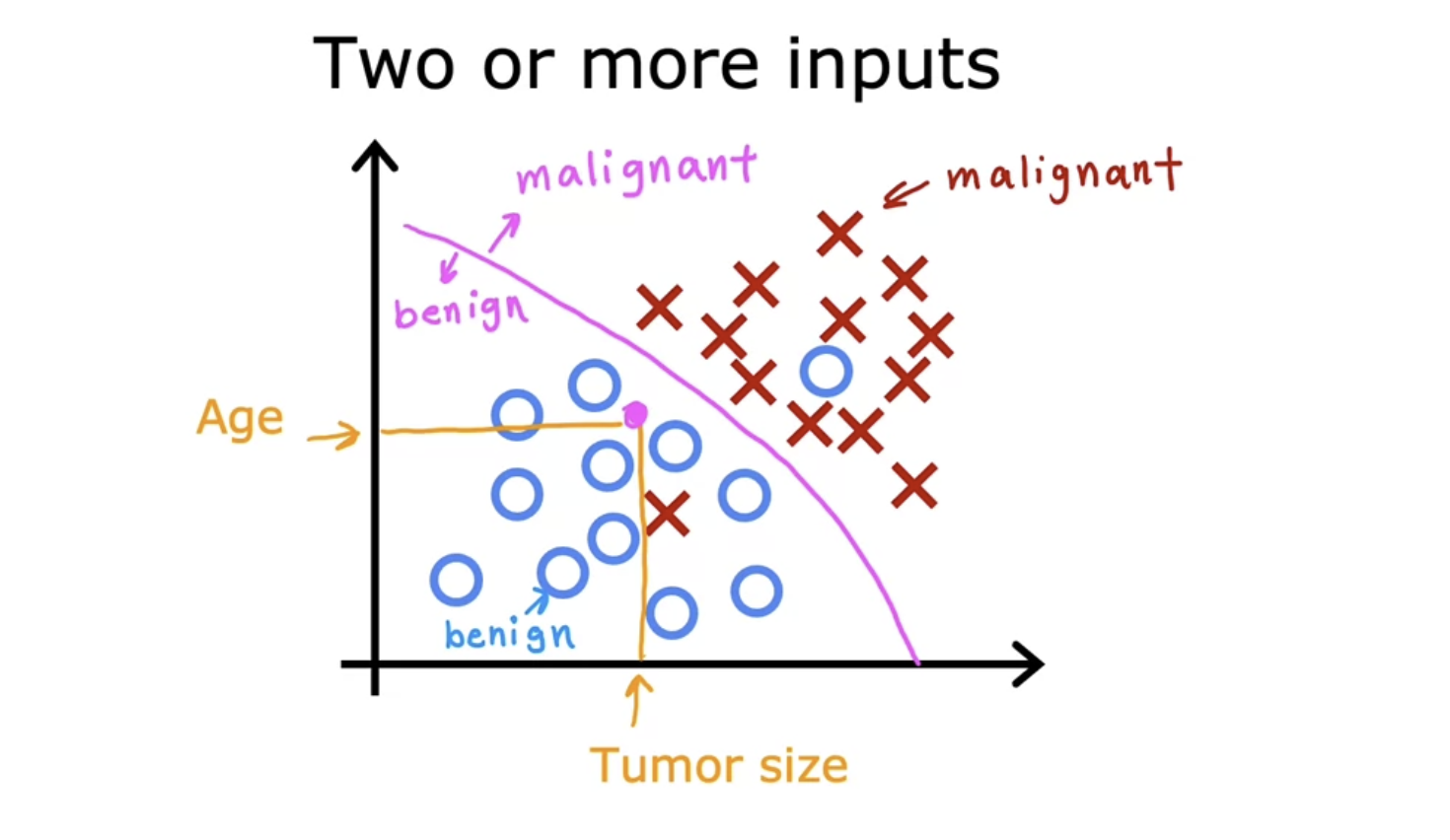
(2) Classification
Predict categories(classes), which don’t have to be a numerical number
One reason that classfication is different from regression is that it predict only a small number of possible outputs or categories.
The terms of output classes and output categories are often used interchangeably.
- 출처 : 코세라 강의
Classification algorithms predict which of k categories some input belongs to. To solve this task, the learning algorithm is usually asked to produce a function $f : R_n→ {1, . . . , k}$. When $y = f(x)$, the model assigns an input described by vector $x$ to a category identified by numeric code $y$. There are other variants of the classification task, for example, where f outputs a probability distribution over classes.
- 출처 : Deep Learning (Adaptive Computation and Machine Learning series)
Unsupervised Learning
Learns patterns or structure on his own from unlabeled dataset
We do not supervise the algorithm, We do not give it the right answer
- 출처 : 코세라 강의
Unsupervised algorithms are those that experience only “features” but not a supervision signal.
The algorithm output value is a feature, not a target provided by a supervisor
Unsupervised learning is the algorithm extracting information(features) from a distribution that do not require human labor to annotate examples.
The term(Unsupervised learning) is usually associated with density estimation, learning to draw samples from a distribution, learning to denoise data from some distribution, finding a manifold that the data lies near, or clustering the data into groups of related examples.
A classic unsupervised learning task is to find the “best” representation of the data. By “best” we can mean different things, but generally speaking we are looking for a representation that preserves as much information about $x$ as possible while obeying some penalty or constraint aimed at keeping the representation simpler or more accessible than $x$ itself
There are multiple ways of defining a simpler representation. Three of the most common include lower-dimensional representations, sparse representations, and independent representations. Low-dimensional representations attempt to compress as much information about x as possible in a smaller representation. Sparse representations embed the dataset into a representation whose entries are mostly zeros for most inputs. The use of sparse representations typically requires increasing the dimensionality of the representation, so that the representation becoming mostly zeros does not discard too much information. This results in an overall structure of the representation that tends to distribute data along the axes of the representation space. Independent representations attempt to disentangle the sources of variation underlying the data distribution such that the dimensions of the representation are statistically independent
- 출처 : Deep Learning (Adaptive Computation and Machine Learning series)
Types
Clustering
: groups similar data together
Anomaly Detection
: find unusual data
Dimensionality Reduction
: compress a big data-set to a much smaller data-set while losing as little information as possible
Terms
- Machine Learning
- Representation
- Regression
- Classification
- Category
- Class